|
I am a Ph.D. student in Electrical Engineering at Indian Institute of Technology Gandhinagar, advised by Prof. Shanmuganathan Raman. My research interests include 3D‑aware generative modeling with a special focus on creating realistic and animatable virtual humans. I am also interested in motion understanding across human and non‑human species. I was previously a Visiting research scholar at Multimedia and Human Understanding Group (MHUG) group at the University of Trento, supervised by Prof. Nicu Sebe. Earlier, I worked as a Research Intern with the Visual Intelligence team at Samsung Research Institute Bangalore (SRIB). |

|
|
|

|
Shashikant Verma, Shanmuganathan Raman, BMVC, 2025 We introduce PanoHair, a model that estimates head geometry as signed distance fields using knowledge distillation from a pre-trained generative teacher model for head synthesis. Our approach enables the prediction of semantic segmentation masks and 3D orientations specifically for the hair region of the estimated geometry. Our method is generative and can generate diverse hairstyles with latent space manipulations. Given the latent code, PanoHair generates a clean manifold mesh for the hair region in under 5 seconds, along with semantic and orientation maps, marking a significant improvement over existing methods, as demonstrated in our experiments. |
|
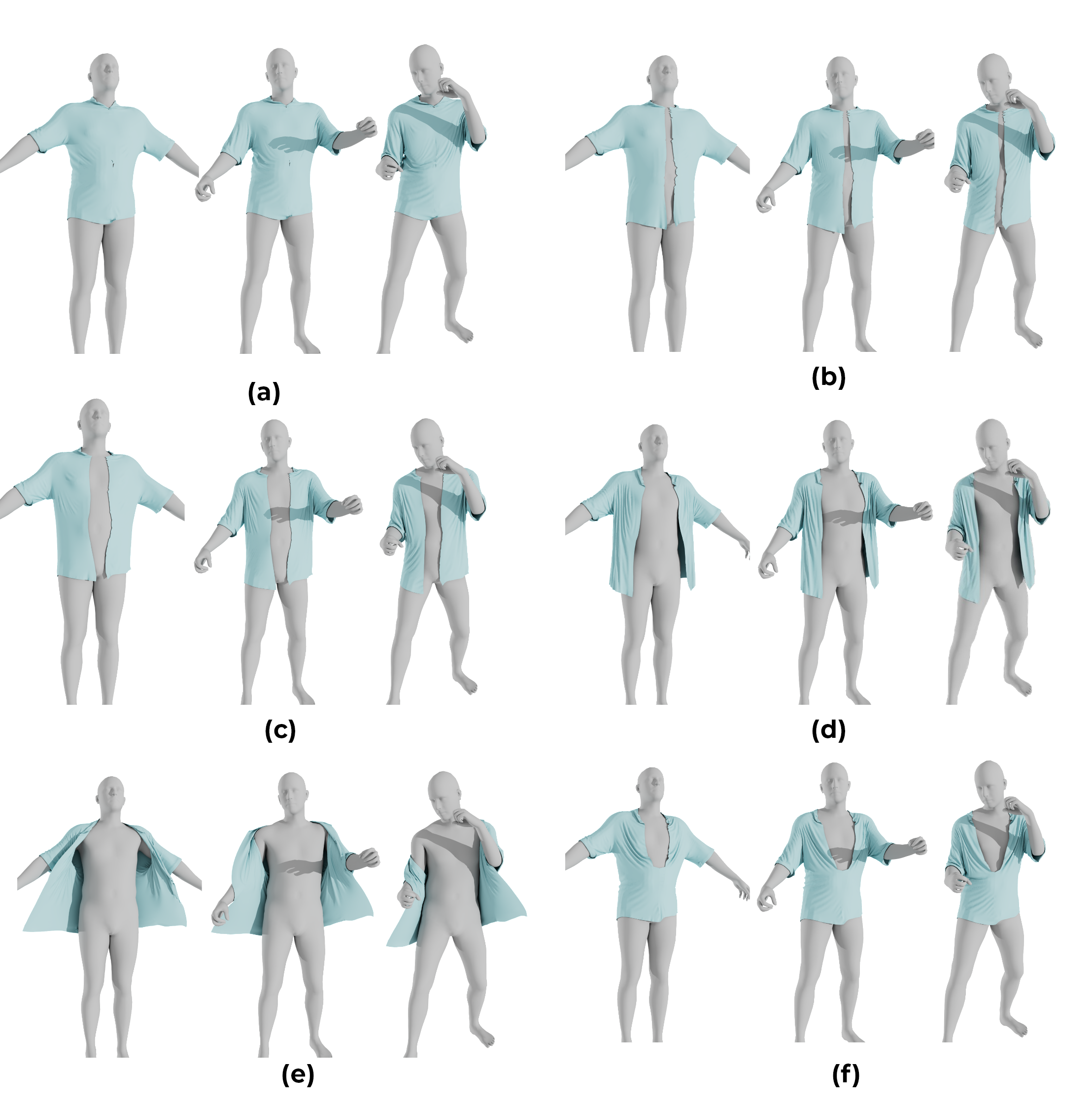
Shashikant Verma, Shanmuganathan Raman, ICIP, 2025 We introduce Deformable Animation Ready Templates (DARTs) to address these challenges, which enhance template based garment reconstruction. Our framework employs a robust feature-line regressor network to establish precise deformation constraints guided by input image characteristics. Additionally, we present a novel differentiable Constrained Rigid Deformation Layer (CRDL) that facilitates effective template deformation while preserving the essential geometry of the garment. |
 |
Shashikant Verma, Nicu Sebe, Shanmuganathan Raman, ICIP, 2025 We introduce GMOT-Mamba, a novel Mamba-based model prediction framework for Generic Multiple Object Tracking (GMOT) in video sequences. Our approach features a Weighted Feature Pooling (WFP) layer, which processes encoded target states, and an innovative encoder-decoder architecture that leverages Vision-Mamba (ViM) to predict filter weights. |
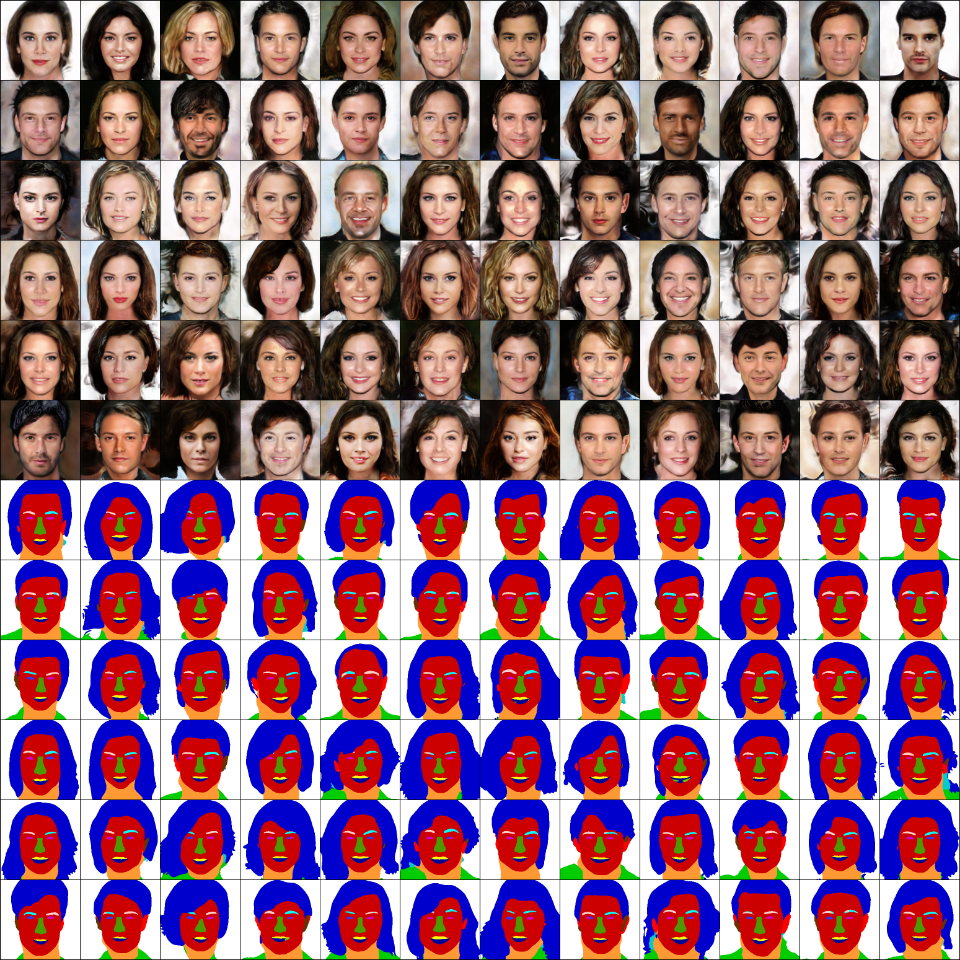 |
Shashikant Verma, Shanmuganathan Raman, ICPR, 2025 This work introduces SemFaceEdit, a novel method that streamlines the appearance and geometric editing process by generating semantic fields on generative radiance manifolds. Utilizing latent codes, our method effectively disentangles the geometry and appearance associated with different facial semantics within the generated image. In contrast to existing methods that can change the appearance of the entire radiance field, our method enables the precise editing of particular facial semantics while preserving the integrity of other regions. |
 |
Soumyaratna Debnath, Harish Katti, Shashikant Verma, Shanmuganathan Raman, ICASSP, 2025 We propose a hybrid approach that utilizes rigged avatars and the pipeline to generate synthetic datasets to acquire the necessary 3D annotations for training. Our method introduces a simple attention-based MLP network for converting 2D poses to 3D, designed to be independent of the input image to ensure scalability for poses in natural environments. Additionally, we identify that existing anatomical keypoint detectors are insufficient for accurate pose retargeting onto arbitrary avatars. |
 |
Shashikant Verma, Aman Sharma, Roopa Sheshadri, Shanmuganathan Raman, WACV, 2024 We present a novel coarser-to-finer approach for deep graphical image inpainting that utilizes GraphFill, a graph neural network-based deep learning framework, and a lightweight generative baseline network. We construct a pyramidal graph for the input-masked image by reducing it into superpixels, each representing a node in the graph. The proposed pyramidal approach facilitates the transfer of global context from coarser to finer pyramid levels, enabling GraphFill to estimate plausible information for unknown node values in the graph |
 |
Shashikant Verma, Subramanian Sankaranarayanan, Shanmuganathan Raman, SPCOM, 2024 In this work, we present a method for precisely segmenting individual petals within flower images. Petal segmentation is challenging due to its intricate structures and substantial variations among petals across diverse flower species. Moreover, frequent occlusions and the uniformity in appearance and shape of petals within a single flower add complexity to the segmentation process, making it error-prone. We introduce a generalized approach to segment petal instances for any flower species. |
 |
Shashikant Verma, Aalok Gangopadhyay, Shanmuganathan Raman, ICPR, 2022 We present Deep Mesh Denoising Network (DMD-Net), an end-to-end deep learning framework, for solving the mesh denoising problem. DMD-Net consists of a Graph Convolutional Neural Network in which aggregation is performed in both the primal as well as the dual graph. |
 |
Shashikant Verma, Rajendra Nagar, Shanmuganathan Raman, CVIP, 2019 In this work, we address the problem of extracting high dimensional, soft semantic feature descriptors for every pixel in an image using a deep learning framework. Existing methods rely on a metric learning objective called multi-class N-pair loss, which requires pairwise comparison of positive examples (same class pixels) to all negative examples (different class pixels). Computing this loss for all possible pixel pairs in an image leads to a high computational bottleneck. We show that this huge computational overhead can be reduced by learning this metric based on superpixels. |